In this post, let us discuss slicing in python with examples.
How Indexing works ?
For your reminder, Indexing starts from zero. In the below example, a[0] & a[1] help us to get the element present in the zeroth and first index position
Program
print("creating a new list")
a=[9,8,7,6,5,4,3,2,1]
print("printing the elements of the list")
print(a)
print("printing the first element")
print(a[0])
print("printing the second element")
print(a[1])
Output
creating a new list
printing the elements of the list
[9, 8, 7, 6, 5, 4, 3, 2, 1]
printing the first element
9
printing the second element
8
What is Slicing ?
Slicing in python helps us in getting the specific range of elements based on their position from the collection.
Here comes the syntax of slicing which lists the range from index position one to two. It neglects the element present in the third index. Below is the official document https://docs.python.org/2.3/whatsnew/section-slices.html
Slicing in Python
Program
a=[9,8,7,6,5,4,3,2,1]
print("printing the first 3 elements of a list")
print(a[0:3])
print("other way to print first 3 elements of a list")
print(a[:3])
Output
printing the first 3 elements of a list
[9, 8, 7]
other way to print first 3 elements of a list
[9, 8, 7]
Positive and Negative indexing in slicing
There are two types of indexing available :
1) Positive Indexing 2) Negative Indexing
Positive Indexing
Program
a=[9,8,7,6,5,4,3,2,1]
print("printing second and third element in a list")
print(a[1:3])
Output
printing second and third element in a list
[8, 7]
Negative indexing
Program
a=[9,8,7,6,5,4,3,2,1]
print("printing the last element")
print(a[-1])
print("printing last three elements in a list")
print(a[-3:])
print("printing from second element till second last element")
print(a[1:-1])
Output
printing the last element
1
printing last three elements in a list
[3, 2, 1]
printing from second element till second last element
[8, 7, 6, 5, 4, 3]
Interview Q&A
How to reverse the elements present in a list?
Program
a=[9,8,7,6,5,4,3,2,1]
print("Reversing the elements")
print(a[::-1])
Output
Reversing the elements
[1, 2, 3, 4, 5, 6, 7, 8, 9]
In this post, we will see ag grid angular examples. ag grid is one of the most commonly used grid in modern web applications. It is easy to integrate with java script, angular. react ,vue.js.
In this post, we will learn about create dataframe in python using pandas. There are multiple ways to create dataframe in python
DataFrame
Dataframe is one of the data types in python as like string, int. It will look like a table.
It consists of rows and columns. We can say that it is a two-dimensional array.
Here we are using pandas to create the data frame. Pandas is a fast and powerful open-source package. For More details refer the doc below https://pandas.pydata.org/
Installing Pandas Libraries using pip
pip install pandas
Installing Pandas libraries using conda
conda install pandas
In order to use pandas, we should install a pandas package on our machine. Open the terminal/Command prompt and run any one of the above commands Once you installed we need to import using the import command below
import pandas as pd
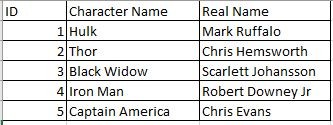
Here I am going to create a data frame with avengers details as like below image
Below are the multiple ways to create dataframe in python using pandas.
Created Dataframe using List
ID Character Name Real Name
0 1 Hulk Mark Ruffalo
1 2 Thor Chris Hemsworth
2 3 Black Widow Scarlett Johansson
3 4 Iron Man Robert Downey Jr
4 5 Captain America Chris Evans
In the above example, we have created a data frame using the list.
Created Dataframe using dict
ID Character Name Real Name
0 1 Hulk Mark Ruffalo
1 2 Thor Chris Hemsworth
2 3 Black Widow Scarlett Johansson
3 4 Iron Man Robert Downey Jr
4 5 Captain America Chris Evans
Here we are created a data frame using the dictionary. Printed the output.
3. Create data frame from csv file
In the below code, we are importing a CSV file as a data frame with the help of pandas library
import pandas as pd
df_avenger_data_csv = pd.read_csv("D://avenger_details.csv")
print("Created Dataframe using csv file")
print(df_avenger_data_csv)
print("\n")
Output
Created Dataframe using csv file
ID Character Name Real Name
0 1 Hulk Mark Ruffalo
1 2 Thor Chris Hemsworth
2 3 Black Widow Scarlett Johansson
3 4 Iron Man Robert Downey Jr
4 5 Captain America Chris Evans
4. Load Mysql table as dataframe using pandas
To load the MySQL table data as a data frame we need a MySQL connector library. you can install using the below command
pip install mysql-connector-python
Once you installed the MySQL connector in your system. you need to create the MySQL connection object and need to pass the connection object and query to the pandas as below
import pandas as pd
import mysql.connector
mysql_connection = mysql.connector.connect(host="localhost", user="root", password="password", database="avengers")
df = pd.read_sql("select * from avengersdetails", mysql_connection)
print("Created Dataframe from mysql table")
print(df)
mysql_connection.close()
Output
Created Dataframe from mysql table
ID CharacterName RealName
0 1 Hulk Mark Ruffalo
1 2 Thor Chris Hemsworth
2 3 Black Widow Scarlett Johansson
3 4 Iron Man Robert Downey Jr
4 5 Captain America Chris Evans
5. Load Mongodb collection as dataframe
To load the MongoDB collection data as a data frame we need pymongo library. you can install using the below command
pip install pymongo
Once you installed the pymongo in your system. you need to create the MongoDB connection object. After that, you need to convert MongoDB to pandas data frame
Created Dataframe from mongodb collections
_id ID Character Name Real Name
0 5fd0e603549a851a24a48c36 1 Hulk Mark Ruffalo
1 5fd0e603549a851a24a48c37 2 Thor Chris Hemsworth
2 5fd0e603549a851a24a48c38 3 Black Widow Scarlett Johansson
3 5fd0e603549a851a24a48c39 4 Iron Man Robert Downey Jr
4 5fd0e603549a851a24a48c3a 5 Captain America Chris Evans
In this post, let us learn about the difference between map and flatmap in pyspark.
What is the difference between Map and Flatmap?
Map and Flatmap are the transformation operations available in pyspark.
The map takes one input element from the RDD and results with one output element. The number of input elements will be equal to the number of output elements.
In the case of Flatmap transformation, the number of elements will not be equal. That is the difference between the two.
Let the below example clarify it clearly.
How to create an RDD ?
With the below part of the code, an RDD is created using parallelize method and its value is viewed.
Let us discuss the topic below with the created RDD.
# Creating RDD using parallelize method
rdd1=sc.parallelize([1,2,3,4])
rdd1.collect()
The RDD contains the following 4 elements.
[1, 2, 3, 4]
How to apply map transformation ?
# Applying map transformation
rdd1_map=rdd1.map(lambda x : x**2)
# Viewing the result
rdd1_map.collect()
In the below result , the output elements are the square of the input elements. And also the count is equal.
[1, 4, 9, 16]
How to apply flatMap transformation ?
# Applying flatmap transformation
rdd1_second=rdd1.flatMap(lambda x : (x**1,x**2))
# Viewing the result
rdd1_second.collect()
In the below result, we are not finding an equal number of elements as map transformation.
In this post , let us learn about the difference between list and tuple.
What are Lists?
Lists are compound data types storing multiple independent values .
It can accommodate different datatypes like integer, string, float, etc., within a square bracket.
In the below example, we have different types of data getting created with the list.
# Creating lists with multiple datatypes
a = [1, 2, 3, 'a', 'b', 'c', 'apple', 'orange', 10.89]
What are Tuples ?
Tuples are also one of the sequence datatypes as like Lists.
Tuples can be created by storing the data within round bracket or without any brackets.
#Creating tuple with round bracket
b=(1,2,3,'a','b','c','apple','orange',10.89,(6,7,8))
#Creating tuple without any brackets
c=1,2,3,'a','b','c','apple','orange',10.89,(6,7,8)
What is the difference between list and tuple?
Lists are mutable whereas tuples are immutable.
We can change the lists but not the tuples.
program
# Creating list a
a=[1, 2, 3, 'a', 'b', 'c', 'apple', 'orange', 10.89]
# Displaying the data
a
# Displaying the datatype
type(a)
Result
[1, 2, 3, 'a', 'b', 'c', 'apple', 'orange', 10.89]
list
We can append the list as shown below, But we cannot change the tuple.
This is the difference between the tuple and the list.